L’enjeu, lorsqu’on aborde l’amélioration d’une intelligence artificielle dédiée à une fonction précise est que l’on parvienne, petit à petit, à lui déléguer l’optimisation de ses propres résultats, l’amélioration de la qualité de sa réponse au problème que lui pose l’être humain. Il faut qu’elle devienne autonome dans son apprentissage. C’est le passage de sa vie estudiantine, où on l’alimente et on l’évalue, à sa vie professionnelle, où on l’évalue et on la met à jour.
Afin d’offrir un caractère concret à cette théorie, nous la contextualiserons pour un type d’intelligence artificielle spécifique : celle en charge des fonctions de ranking dans un moteur de recherche. L’objet est alors de définir un programme d’apprentissage qui permettrait la montée en compétence automatisée d’une telle IA.
INTRODUCTION
La nécessité d’une représentation « human centric ».
L’apprentissage d’une IA se base sur sa capacité à traiter de grands volumes de données, desquels elle déduira des patterns, qui lui permettront de prédire la qualité d’une réponse, sa pertinence, à une question donnée.
L’évaluation de la qualité réelle de son résultat ne peut cependant se suffire au seul calcul de sa pertinence, et doit systématiquement être confrontée à la perception humaine qui en est reçue. Comme tous les autres domaines de l’IT, l’IA devrait bénéficier des qualités d’un service pour une personne qui la sollicite, puisque produite par l’être humain, pour l’être humain (si on est conforme aux best practice de l’UE). La machine n’a pas d’existence propre et l’évaluation de ses résultats ne peut s’absoudre de son rapport à la personne. D’ailleurs, le RGPD nous donne maintenant le droit de ne pas faire l’objet d’une décision fondée exclusivement sur un traitement automatisé, droit qui pourrait s’inscrire directement dans le sillon du principe qui précède.
L’être humain, limite de l’application des modèles.
La qualité efficace d’une relation entre une IA et un être humain, est alors, comme pour tout outil, dépendant de l’usage réel par rapport à l’usage prévu, et de la perception du résultat fourni par rapport au résultat attendu. C’est dans ces delta, que s’insinue l’influence des “pratiques” du consommateur d’un service, qui, des stratégies prévues par un système de consommation, déploie des tactiques d’action : Il agit dans le cadre imposé, mais d’une manière qui échappe parfois au quadrillage. Des représentations visuelles de cette théorie, celle de Michel de Certeau dans “L’invention du quotidien”, sont les lignes de désir dans les jardins. Ces chemins non balisés qui barrent l’herbe des parcs, tracés par un usage régulier et commun, mais imprévus lors de la conception de la structure.
L’amélioration continue des services ne peut donc se faire sans l’étude des pratiques. Les pratiques constituent, selon la sociologie Bourdieusienne, les processus à l’origine du décalage entre une situation attendue et une situation réelle. Ces situations étant des états particuliers, des “conjonctures objectives” d’une structure, elle-même obtenue à partir de régularités que fournissent les statistiques.
Des orientations pratiques empiriques.
Le présent texte va donc proposer une définition d’un service supporté par une intelligence artificielle. Nous prendrons l’exemple d’un moteur de recherche, de manière à pouvoir évoquer quelques notions concrètes, et donner des exemples de pilotage par la qualité selon le modèle ITIL, qui sera brièvement décrit.
Ensuite, quelques éléments techniques, nécessaires à la compréhension du fonctionnement de l’exemple, seront détaillés pour parvenir à établir de paramètres de qualité de service sur lesquels les pratiques de l’utilisateur influent directement. C’est en analysant le rapport entre les pratiques de l’utilisateur, dans sa relation au service, et la qualité de service perçues, qu’une intelligence, artificielle ou naturelle, pourra déduire quelle doit être la forme de l’outil la mieux adaptée à un usage, et donc accéder à la personnalisation, objet de la dernière partie de cette étude.
L’objectif de cette théorie est de décrire l’intérêt des pratiques de gestion de service dans l’automatisation de l’optimisation d’une fonction portée par une intelligence artificielle, dans le cadre d’un service qu’elle doit rendre. L’ordre des étapes qui seront décrites est directement inspiré de l’histoire d’Air bnb Experiences et de leur transition d’un modèle d’offline ranking à un modèle d’online ranking, soit une fonction de ranking ML-based, capable d’apprendre de ses expériences et de s’adapter dynamiquement à l’utilisateur qu’elle sert.
ÉTAPE 1 : MODÉLISER LE SERVICE ET MESURER SA QUALITÉ
Le modèle ITIL
Pour modéliser la fourniture du service, nous utiliserons le modèle ITIL. C’est un ensemble de meilleures pratiques empiriques issu de l’analyse du fonctionnement des fournisseurs de services du marché. Ce référentiel est souvent associé aux normes ISO9000 et ISO20000.
Il faut rappeler qu’un service n’existe que parce qu’un consommateur le consomme. C’est ce qui le distingue des produits sur lesquels il repose, et dont l’existence n’est pas nécessairement dépendante de leur rapport à l’individu. C’est dans la prégnance de cette relation que le modèle ITIL est adapté à notre étude. Le marché de l’IT s’est transformée en industrie du service au point que la majorité des produits sont proposés en services, au nom de la mutualisation : des IaaS, au PaaS, au SaaS, aux micro-services, etc. Il y a une normalisation conceptuelle des modèles convergeant vers le service, qui pourrait presque traduire l’affirmation du rôle de la technologie envers l’humain.
ITIL est donc un modèle holistique dans le sens où les éléments qu’il définit sont tous interdépendants, comme l’Indra’s net des bouddhistes : La modification des parties modifie le Tout, la modification du Tout passe par ses parties.
L’objectif de ce parti-pris est que le besoin de l’utilisateur et/ou du client doit influer sur la définition systémique du service, et tout changement d’un élément de production doit être réalisé en connaissances des impacts prévus pour l’utilisateur.
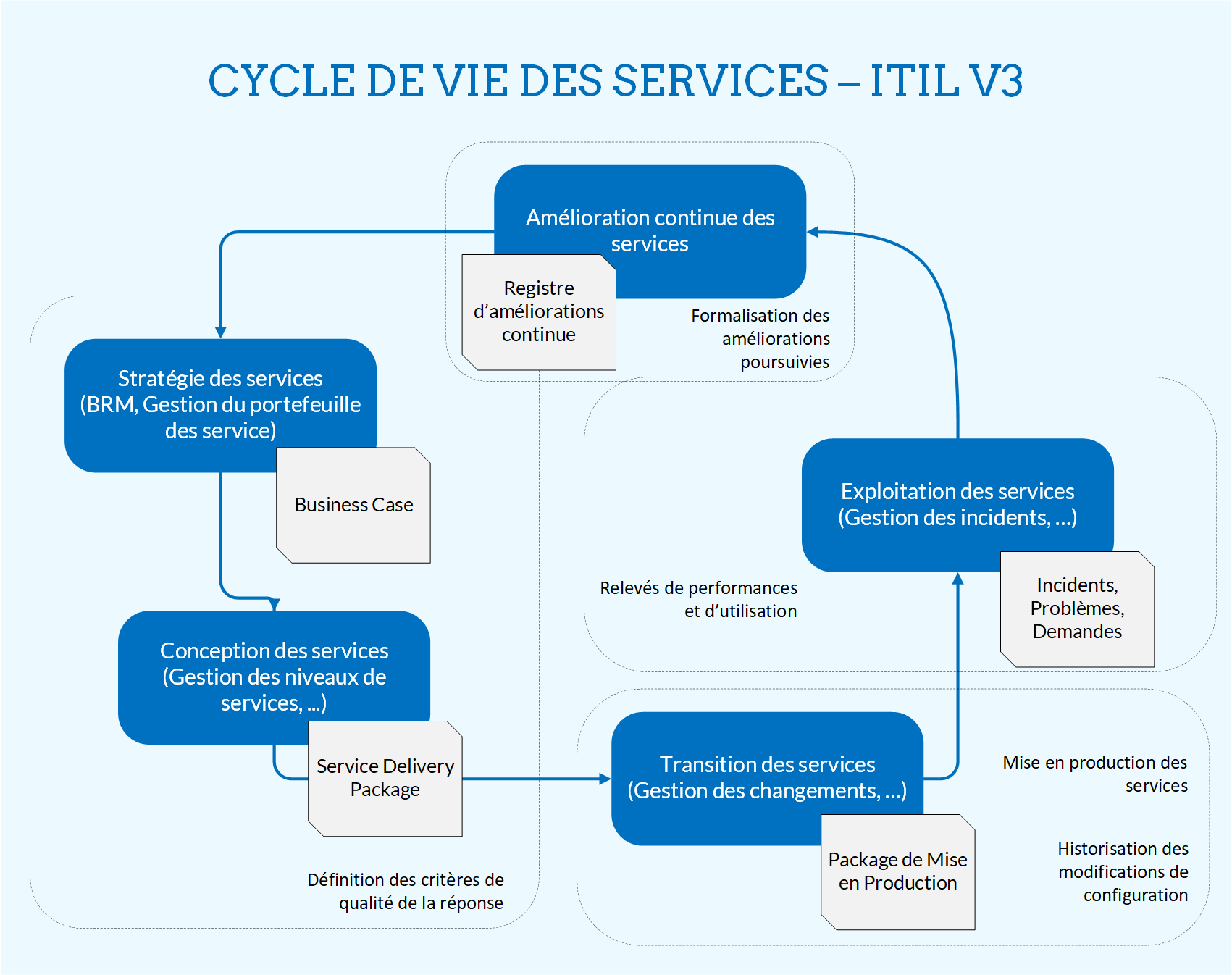
Dans la suite du document nous utiliserons la terminologie du modèle V3. C’est celle que je connais, mais je serais heureux qu’un parallèle puisse être fait avec le modèle 4. ITIL V3 préconise une structure organisationnelle du fournisseur IT qui puisse supporter les processus des différentes phases du « cycle de vie des services ». Elles sont au nombre de cinq : la stratégie de services, la conception de services, la transition de services, l’exploitation de services et l’amélioration continue des services. Chaque phase est incarnée par un ensemble de processus qui servent les fonctions de la phase. Ceux de la stratégie priorisent les actions du fournisseur de services IT en fonction des objectifs business, de la vision. Ceux de la conception formalisent les accords de niveaux de service et les services que proposent un fournisseur dans son catalogue. La transition de service assure que les mises en production sont maîtrisées et répondent aux attentes métiers. L’exploitation garantit le maintien en conditions opérationnelles et alimente l’amélioration continue des informations de production. Il faudra alors les croiser aux remontées business pour proposer des évolutions à la stratégie, et le cycle reprendra. Chaque processus dépend des autres, que ce soit ceux de sa phase, ou ceux d’une autre.
Les représentations du cycle sont diverses, je vous en propose la suivante qui présente juste l’intérêt d’être simplifiée, même si elle s’avère catégorisante. J’ai associé aux phases certains livrables qu’elles permettent de générer et qui ont leur intérêt pour la théorie qui va suivre.
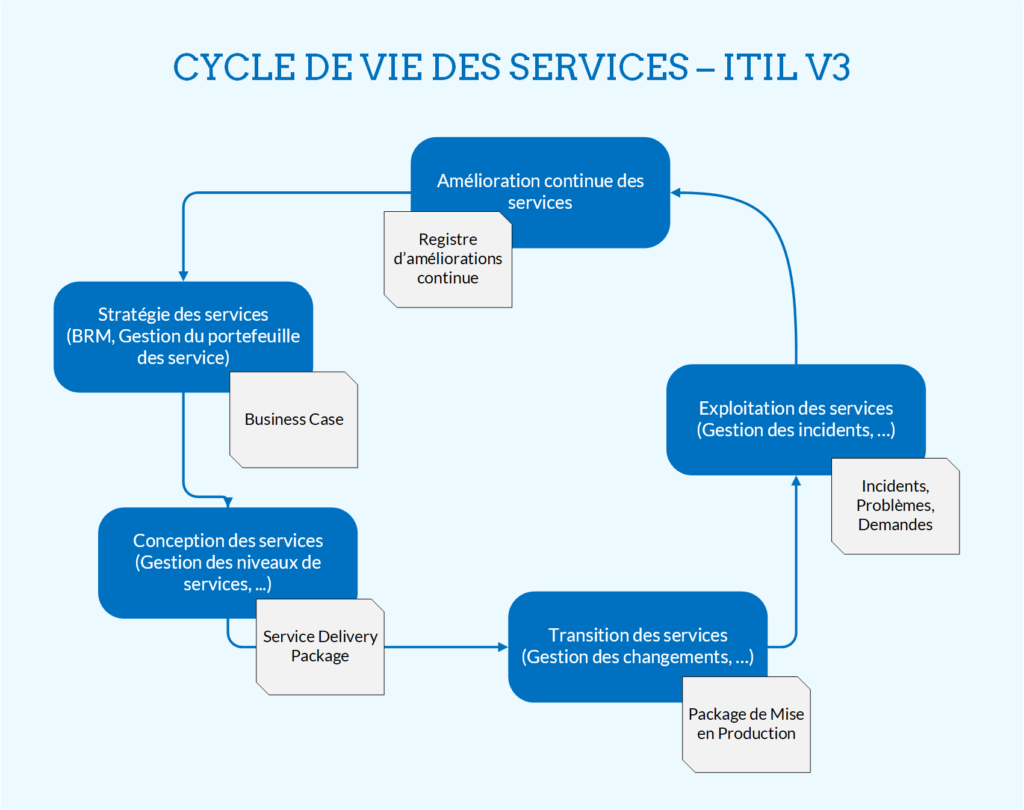
La structure du service dans le modèle ITIL a donc pour objectif de lier les moyens de production (les serveurs, le réseau, les algorithmes au sein des programmes, ainsi que les personnes qui les développent et les maintiennent), aux besoins du client ou de l’utilisateur, qui en définissent la valeur réelle.
Les processus des phases de stratégie et de conception sont en charge de définir les métriques, traduisant des objectifs mesurables de la vision. Ces indicateurs nous apporterons ensuite le feedback sur la qualité du service, durant les phases de test et d’exploitation, pour en piloter l’amélioration.
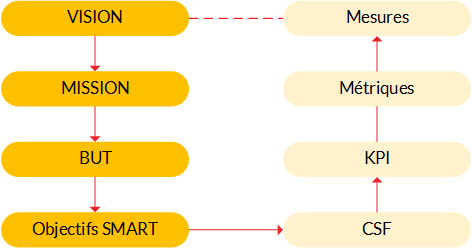
Pour contextualiser un peu le modèle et en faciliter l’appréhension, nous allons étudier sa possible application à un moteur de recherche, et donner quelques exemples d’indicateur de qualité.
Stratégie et conception d’un service de recherche
La structure du moteur de recherche sera sa représentation au sein du modèle ITIL. Dans ce référentiel, un service de recherche est un ensemble de fonctionnalités et de garanties, formalisées par les accords de niveaux de services, qui permet à un individu d’utiliser un système de gestion de la connaissance (SKMS) supporté par un modèle DIKW (Data → Information → Knowledge → Wisdom).
Ce SKMS, le système du moteur de recherche, permet à un utilisateur d’accéder à une information (i.e des données contextualisées et structurées), traduite en connaissance (i.e une information ordonnée qui aide à la compréhension et à la décision), pour atteindre la sagesse, qui ouvre aux décisions éclairées.
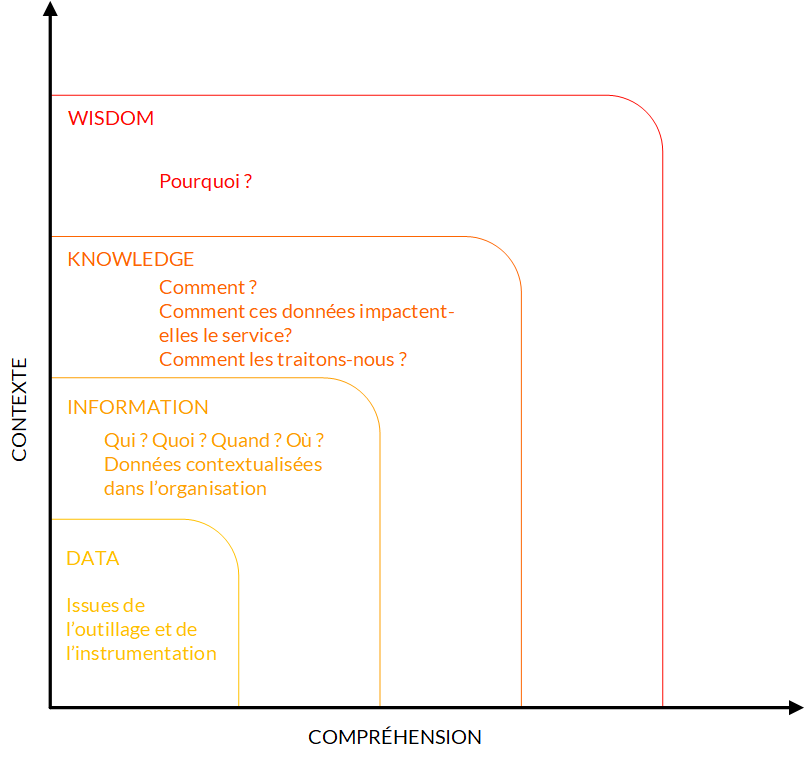
Lorsqu’un utilisateur entre une requête dans un moteur, son besoin est d’accéder à la réponse qui correspond le mieux à la question qu’il se pose.
La qualité du service peut donc être mesurée par un ensemble d’indicateurs, tels que :
- le taux de clics sur le premier lien de l’index pour une même requête, qui indique que l’index répond efficacement à la requête.
- le
taux de requêtes pour lesquelles l’utilisateur a consulté plusieurs
liens de l’index, qui indique que l’index n’est pas suffisamment
efficient. - Le temps moyens d’affichage des résultats sur le frontend, dont dépend la qualité de l’expérience utilisateur.
- Etc.
L’objet de cette première étape est donc d’établir des critères de qualité mesurables relatifs aux résultats proposés à l’utilisateur par le service. A ces derniers, il faudrait ajouter des indicateurs de garantie, tel que la disponibilité, la capacité, la continuité ou la sécurité du service, pour avoir une représentation de la qualité globale à un instant donné.
Ainsi, d’une structure du service, nous pourrions dériver des situations, conjonctures liées à l’usage, sous la forme des relevés de qualité du service. On aurait, à un instant donné, un état de la qualité du service qu’on fournit. Il nous resterait alors, selon Bourdieu, à comprendre le décalage entre les pratiques et ces structures, le décalage entre les objectifs de qualité fixés et la qualité réelle.
Il est à noter que la première étape qu’a suivi Airbnb, pour parvenir à un modèle d’online ranking, fut de définir les critères de qualité des résultats soumis à l’utilisateur. Ces indicateurs était initialement des relevés des interactions utilisateurs avec les éléments indexés, comme le taux de clics sur un élément parmi toutes les requêtes qui le proposaient. Ils allaient alors exploiter l’historique de qualité des résultats pour supporter l’évolution de leur modèle. C’est le rôle du pilotage par la qualité de l’ITSM.
La deuxième étape qu’ils suivirent fut de définir un modèle de personnalisation. Étudions donc les leviers de personnalisation pour un moteur de recherche qui n’enregistrerait aucune données à caractère personnel, cela facilitera notre conformité RGPD.
Dans la suite du document, nous considérerons que les métriques sont définies et revues régulièrement, comme le favorise l’application du modèle de gestion de service. Pour simplifier la théorie, nous appellerons « KPI », l’ensemble des indicateurs qui permettent d’évaluer la qualité du service, la satisfaction du besoin utilisateur par le produit d’intelligence artificielle. Nous étudierons l’apport potentiel des autres phases du cycle de vie des services pour aboutir à une automatisation possible de l’optimisation du service.
ÉTAPE 2 : DÉVELOPPER LA PERSONNALISATION EN ÉTUDIANT LES PRATIQUES DE CONSOMMATION DES SERVICES.
Modélisation des pratiques d’utilisation d’un service de recherche.
La valeur des KPI pour une requête soumise à un moteur de recherche traduit la qualité de l’index au regard de cette dernière. L’ordre des résultats proposés à l’utilisateur est défini par la fonction de ranking. Elle ordonne l’index selon les valeurs de sa fitness function, qui établissent de la pertinence, la suitability d’un lien, par rapport à la requête d’un individu. Ces fonctions considèrent énormément de paramètres. Cependant, on peut distinguer des catégories spécifiques pour regrouper ces derniers :
- Les query features : paramètres, ou features,
relatifs à la requête de l’utilisateur. Exemple : le nombre de termes
dans la recherche, la langue de la recherche, la catégorie NLP de la
requête (porno, bricolage, etc.), etc. - Les query/document features :
paramètres qui mesurent l’adéquation d’un lien à une requête, la
pertinence d’un résultat. Ils associent donc la typologie de la requête à
la description de la page web. Exemple : BM25, TF / IDF, etc. - Les document features : elles concernent la page elle-même, le document web. Exemple : taille de l’URL, nombre de slash, page rank, etc.
Les premières sont directement liées à l’entrée utilisateur, les dernières sont construites par le système de gestion de la connaissance. Appelons dorénavant le “Modèle”, le modèle de service qui décrit le moteur de recherche — de son frontend, aux gens qui le maintiennent, en passant par l’intelligence artificielle qui calcule cette fitness function —, et qui en évalue la qualité par des KPI.
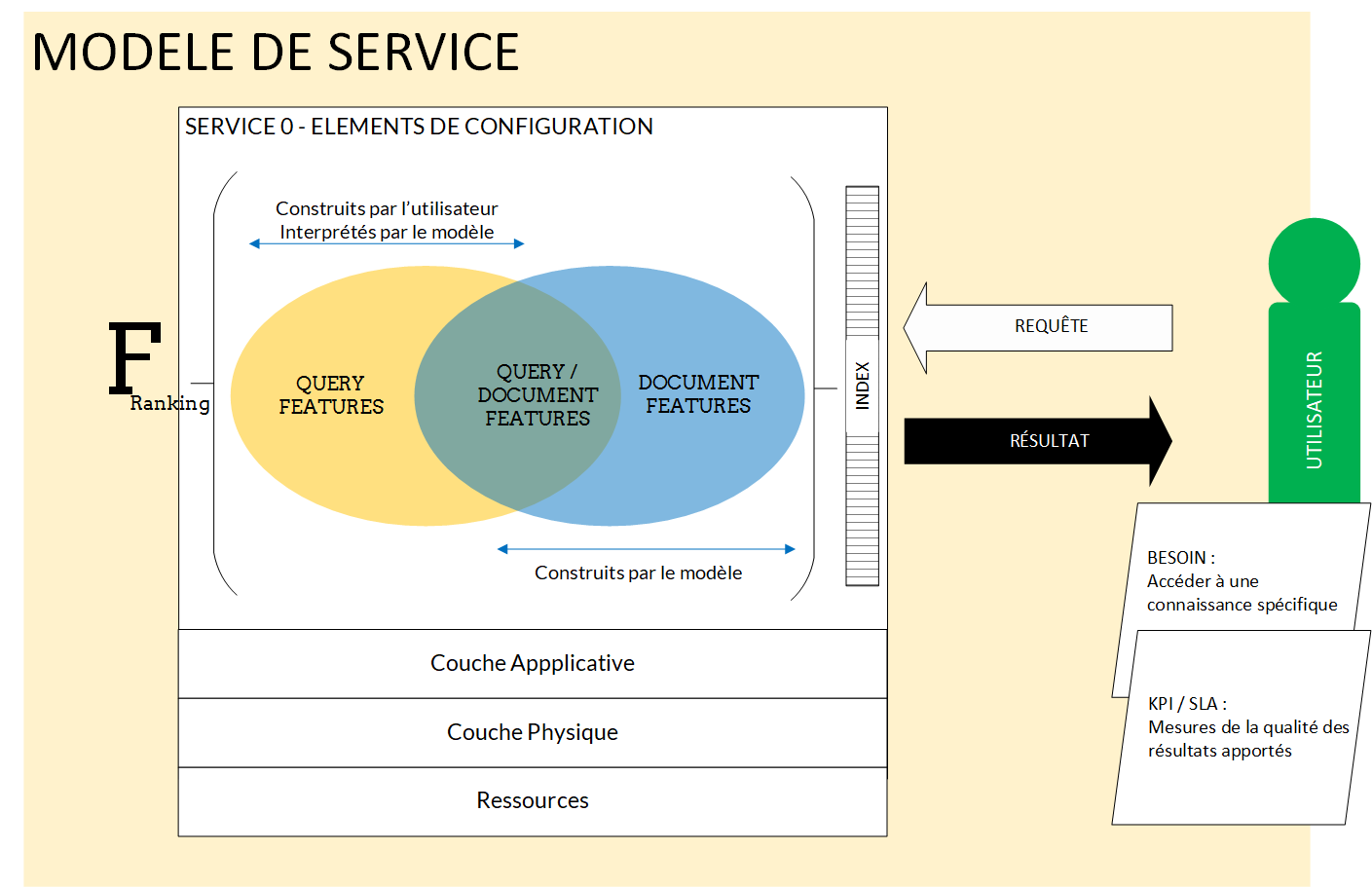
La qualité du “Modèle” est alors celle du SKMS, évoquée au premier chapitre, mais développée, notamment, comme le rapport des résultats de la fitness function de ranking aux KPI du service de recherche censés en mesurer la qualité. Or, la qualité des résultats de la fitness function étant directement dépendante de la formulation de la requête utilisateur, le modèle dispose d’un relevé des « pratiques » de consommation du service, qu’on peut alors lier à la qualité de ce dernier. L’historique des KPI doit être intégré au traitement de la fitness function.
La personnalisation qui amènera à l’optimisation d’une fonction de ranking par l’intelligence artificielle elle-même va donc poursuivre deux objectifs :
- intégrer la qualité de service, les KPI, à la fitness function, en complément des query/document features qui établissent de la pertinence d’un document par rapport à une requête, car les KPI établissent de la pertinence d’un ranking par rapport à un consommateur.
- Piloter la personnalisation par les paramètres de type query features qui,
sans collecte de données personnelles, sont les seules informations
relatives à l’utilisateur. Elles décrivent la manière qu’a ce dernier de
poser des question à un moteur de recherche.
Avant d’aborder les voies de développement de la personnalisation pour un moteur de recherche qui ne collecterait pas de données à caractère personnel, faisons une petite synthèse des paragraphes qui précèdent.
La pertinence d’un résultat proposé par une IA ne peut pas être exclusivement calculée par cette dernière, car toute IA, sur le marché actuel, s’intègre à un service. Elle n’existe donc que dans son rapport à un consommateur, un individu dont l’unicité peut se traduire tant dans ses pratiques que dans ses attributs personnels (son âge, son genre, etc.). La qualité de service de l’IA résiderait alors dans sa capacité à fournir un résultat personnalisé au consommateur. Elle doit apprendre de ce dernier ou de ses pratiques.
Pour une fonction de ranking qui ne pourrait profiter d’informations à caractère personnel sur un utilisateur, la personnalisation pourrait alors passer par une personnalisation par usage, c’est-à-dire dépendant de la formulation des questions qui lui sont posées, qui permettrait de prédire des résultats attendus.
Le chapitre suivant proposera donc des orientations techniques pour initier une démarche de personnalisation supportée par des indicateurs de qualité, les KPI en fonction d’indicateurs de pratiques, dépendant des query features (e.g : le nombre de termes dans la recherche, la langue de la recherche, la catégorie NLP de la requête (type porno, bricolage, etc.), etc.).
Personnaliser le service en fonction de la catégorisation des pratiques.
Un Modèle du service de recherche peut mieux satisfaire certains types de requêtes qu’un autre. Cela se traduit par exemple par la différence des résultats, pour une même requête, que fournissent Google, Qwant, DDG, Bing, etc. Certains utilisateurs préfèrent les services de l’un, alors que d’autres préfèrent les services des autres, d’où la répartition des parts de marché. A l’origine, Bing était d’ailleurs réputé pour la qualité de ses résultats relatifs aux requêtes pornographiques (catégorisation NLP).
Ainsi, avant que l’IA puisse elle-même proposer des améliorations de modèles en fonction des requêtes qui lui sont soumises, un premier niveau de personnalisation pourrait résider dans l’association d’un modèle de configuration à une typologie de requête.
- Comment évaluer la pertinence d’un modèle par rapport à une requête ? Par une
étude régulières des résultats d’un modèle (KPI) en fonction des query features qui sont les seuls paramètres qui offrent une information sur l’utilisateur, sur sa manière de poser les questions. - Comment disposer de suffisamment de résultats pour déduire des patterns
entre la configuration du système et sa capacité à délivrer des
résultats de qualités pour certains types de requêtes ? En récoltant les
performances de nombreux modèles qui seraient éprouvés par des
utilisateurs pour déterminer les tendances, dans leur configuration, qui
garantissent, statistiquement, la qualité des réponses apportées dans
des situations précises dépendantes des query features.
La génération de ses lacs de données nécessaires à l’établissement de corrélations par des data scientist, au-delà de l’étude des résultats de la concurrence, pourrait reposer sur une nouvelle architecture de production.
Puisque les chapitres précédents veillaient à représenter un moteur de recherche comme un service, on pourrait imaginer supporter chaque modèle dans un orchestrateur. En effet, les orchestrateurs modernes ont justement pour rôle d’équilibrer les charges de différents services, sur la base de fonctions complexes. On n’équilibre plus seulement des charges, qui assurent des garanties, mais on peut aussi équilibrer des fonctionnalités, deuxième élément constitutif du service.
Le fournisseur de service devrait formaliser un nouveau processus de gestion des déploiements et des mises en production (processus de la transition de service ITIL), qui veillerait à déployer toute nouvelle version du modèle en production, sans forcément retirer la précédente. Il pourrait ainsi éprouver les différents modèles et comparer leur résultats en fonctions des query features.
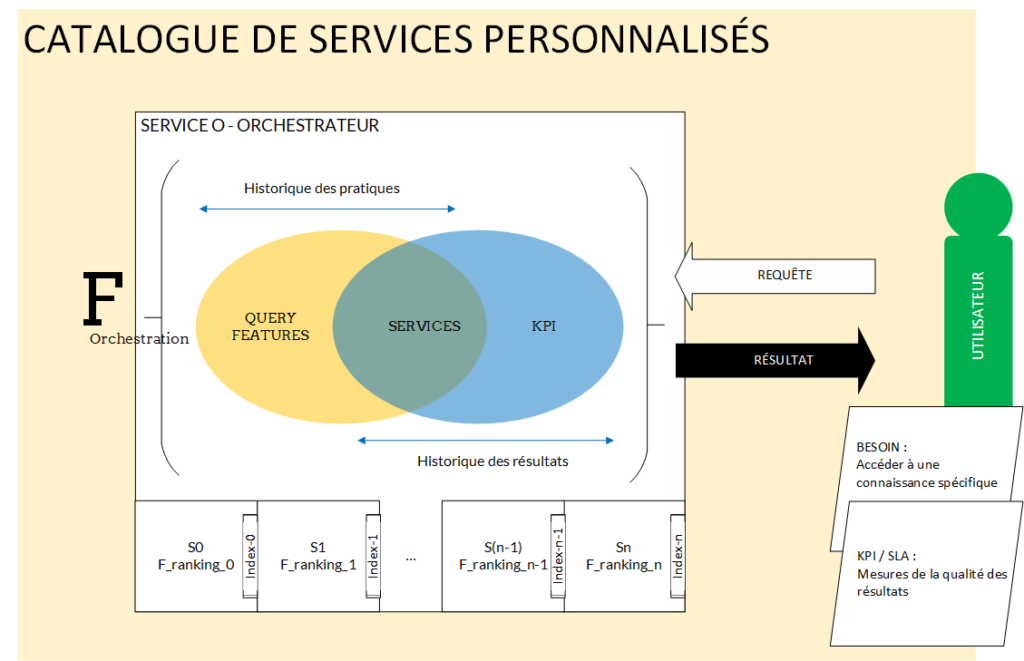
Ainsi, les résultats de la phase d’exploitation des services permettraient, comme supposé par l’ITIL, d’orienter l’amélioration continue du service, qui devrait aboutir à des ajustements de la structures en vue d’augmenter l’efficacité et l’efficience du service.
Les nouvelles versions du services seraient mises en production dans l’orchestrateur, dont la fonction d’orchestration devrait être paramétrée selon les résultats attendus par le changement global du service de recherche, dorénavant composé des différentes versions du modèle en production et de la fonction qui oriente une requête sur un modèle plutôt que sur un autre.
Cette première étape de personnalisation simpliste du service de recherche ne permettrait pas encore l’automatisation de l’optimisation de la fonction de ranking, mais offrirait un caractère de personnalisation dynamique puisque non lié à un index fixe : à chaque requête, son index.
De plus, une implémentation particulière des processus de transition de service ITIL pourrait permettre de décrire, petit à petit, la nature des changements à effectuer pour atteindre des objectifs SMART de qualité.
Le processus de gestion des changements a en effet pour rôle de définir une structure particulière de changement, de la forme du ticket, à son approbation, en passant par la valeur des tests et validations effectués pour assurer que les objectifs attendus par la modification du service sont atteints.
En travaillant sur une catégorisation précise des évolutions apportées à la fonction de ranking, notamment sur les variations de traitement des features en fonction des objectifs de qualité recherchés et/ou atteints pour le nouveau modèle, on pourrait imaginer dégager des tendances de l’impact d’un type de changement sur un modèle existant.
C’est donc en exploitant les données des processus d’exploitation de service et de transition de service, que nous pourrions commencer à automatiser la génération du registre d’amélioration continue qui alimente les phases de stratégie et de conception de service, responsable des demandes de changements soumis à la phase de transition de service.
On aboutit finalement à l’évidence : l’automatisation de l’amélioration de la qualité d’un service nécessite la formalisation de son modèle de production/amélioration, pour qu’il puisse être retranscrit dans d’une machine.
CONCLUSION
Pour les service dont la valeur repose sur les résultats d’une fitness function d’une intelligence artificielle, la problématique de l’automatisation de l’optimisation de la fonction est une problématique d’automatisation des processus de production du service.
Mais toute automatisation d’un processus passe d’abord par sa modélisation. Pour que la machine puisse apprendre les pratiques dont nous usons pour l’améliorer, nous devons pouvoir lui décrire ces dernières.
Pour s’engager sur la voie d’une fonction de ranking ML based, un fournisseur de service de recherche pourrait alors initier la représentation du modèle de service qui pilote les évolutions des services qu’il délivre afin, d’un jour, permettre à la machine de les assimiler, pour qu’elle puisse à son tour proposer — et peut-être même appliquer — les modifications les plus pertinentes pour l’atteinte d’un objectif souhaité, répondant à un besoin humain.
L’intérêt d’un SKMS qui s’adapterait aux pratiques de l’utilisateur, et non à l’utilisateur lui-même, c’est qu’il lui offrirait la possibilité d’accéder à des connaissances différentes en variant ses pratiques : paraphrasez-vous pour être mieux compris.
Tout ceci n’est qu’une théorie, mais elle est aussi une lecture de l’expérimentation d’Airbnb par l’approche du service. Elle nécessiterait cependant plus d’applications pour être éprouvée.
L’opportunité philosophique de ces réflexions est qu’il est étonnant de percevoir le rôle des Intelligence Artificielles comme des programmes devant juger, seuls, de la pertinence d’une solution à un problème posé par l’être humain. On pourrait alors définir la faculté de juger selon l’interprétation de De Certeau de la philosophie Kantienne : « Le jugement ne porte pas sur la seule « convenance » sociale (équilibre élastique d’un réseau de contrats tacites) mais, plus généralement, sur le rapport d’un grand nombre d’éléments, et il n’existe que dans l’acte de créer un ensemble nouveau par une mise en relation convenable de ce rapport avec un élément de plus ». Les critères de personnalisation permettraient à une I.A d’intégrer un élément additionnel — élément propre à chaque pratique humaine — à des « convenances », qui bénéficieront alors d’une contextualisation plus riche, pour que l’IA fasse elle-même le chemin d’un service d’information à un service de connaissance, en densifiant ses éléments de contexte (cf. le modèle DIKW). Une fois qu’elle devient en mesure d’optimiser seule sa fonction de jugement, on peut s’imaginer que l’être humain a parfait son « art de faire des calculs », en tant « qu’inventivité incessante d’un goût dans l’expérience pratique ».